
阅读一些文献
8 paper shared by Teacher
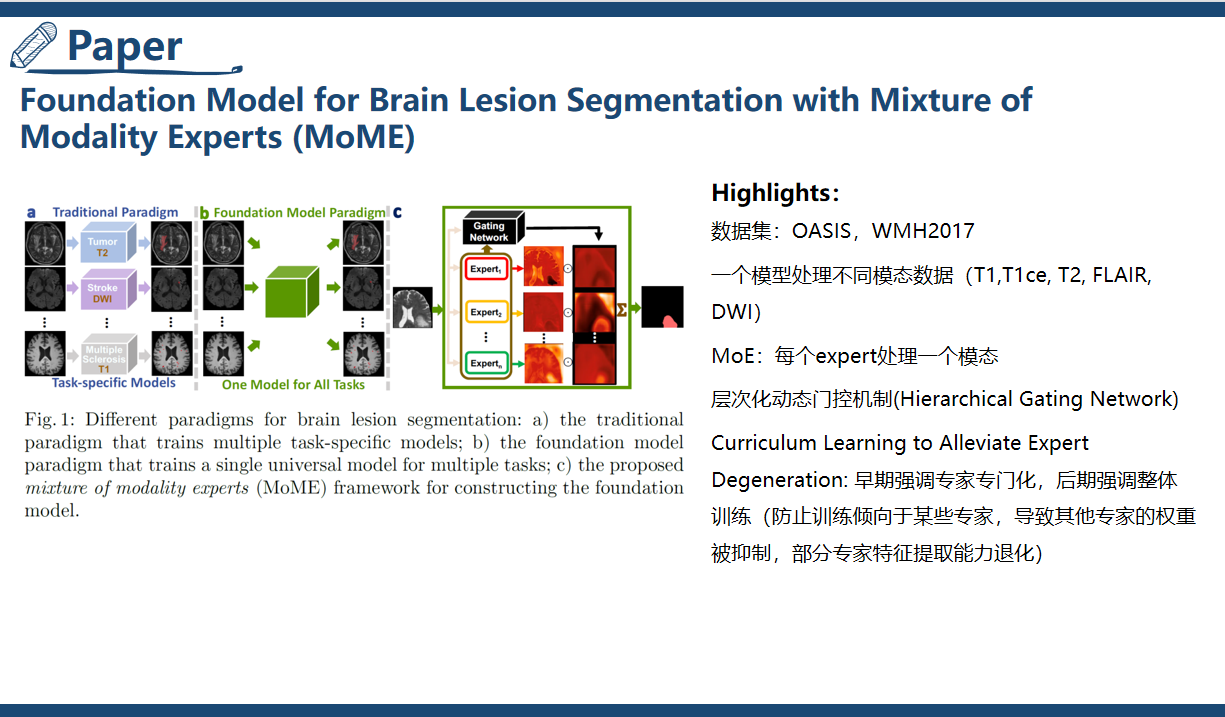
Paper 1: Foundation Model for Brain Lesion Segmentation with Mixture of Modality Experts (MoME)
The paper locates at P379-389
MoME代码链接:https://github.com/ZhangxinruBIT/MoME
MoME 简介
MoME (Mixture of Modality Experts) is a task-agnostic universal foundational model for brain lesion segmentation.
Keypoints
- Architecture
- expert network : A team of experts, each of whom is specialized to be able to handle a particular imaging modality.
- gates network : Like a decision-maker, who ensembles the expert networks by dynamically adjusting the weights of their outputs with hierarchical guidance.
- Training Strategy
- A curriculum learning strategy to avoid the degeneration of each expert network and preserve their specialisation
Multi-Resolution Encoder-Decoder Architecture
This concept appeared at Expert Specialization, Detailed Design.
多分辨率编码器-解码器架构(Multi-Resolution Encoder-Decoder Architecture)是一种深度学习模型设计,广泛应用于计算机视觉、图像处理、医学影像分析等领域。其核心思想是使用编码器-解码器结构,通过多分辨率的特征提取,将不同分辨率的特征融合,以增强模型的表达能力。由编码器、解码器和多分辨率模块(例如金字塔池化模块、空洞卷积、多分支结构等)组成。
文中提到的U-Net就是一种典型的编码器-解码器结构。
Voxel-Wise
This concept appeared at Hierarchical Gating Network, Detailed Design.
体素级(Voxel-Level) 是指在三维空间中对数据进行处理和分析的最小单位,类似于二维图像中的像素(Pixel),但在三维空间中称为体素(Voxel)。体素是三维图像的基本单元,是一个立方体单元,包含位置信息和强度值(灰度、颜色等),通常用于医学影像分析、计算机视觉、三维重建等领域。体素的大小决定了三维图像的分辨率,体素越小,分辨率越高。
Dice
This concept appeared at Experiments.
Dice是一种常用的评估指标,广泛应用于图像分割、目标检测等任务中,用于衡量预测结果与真实标签之间的相似性。Dice 系数(Dice Coefficient)和 Dice 损失(Dice Loss) 是深度学习中常用的工具。
Dice coefficient
- $A$ 是预测结果, $B$ 是真实标签。
- $|A \cap B|$ 是预测结果与真实标签的交集。
- $|A|$ 和 $|B|$ 分别是预测结果和真实标签的大小。
- Dice值范围为[0,1],1表示完全匹配,0表示完全不匹配。
Dice loss
- Dice loss是基于Dice的损失函数。
- $\epsilon$ 是小常数,避免分母为0。
- 用概率值代替二进制值,可以得到适用于深度学习模型的变体Soft Dice Loss:
- 优点: Dice损失对类别不平衡问题具有鲁棒性,且能直接优化重叠区域,适合分割任务。
鲁棒性:系统、算法或模型在面对异常输入、噪声、干扰或参数变化时,仍能保持稳定性和有效性的能力。 - 缺点: Dice损失对边界区域的敏感性较低,在极端情况下(如预测结果和真实标签都为空),可能导致数值不稳定。
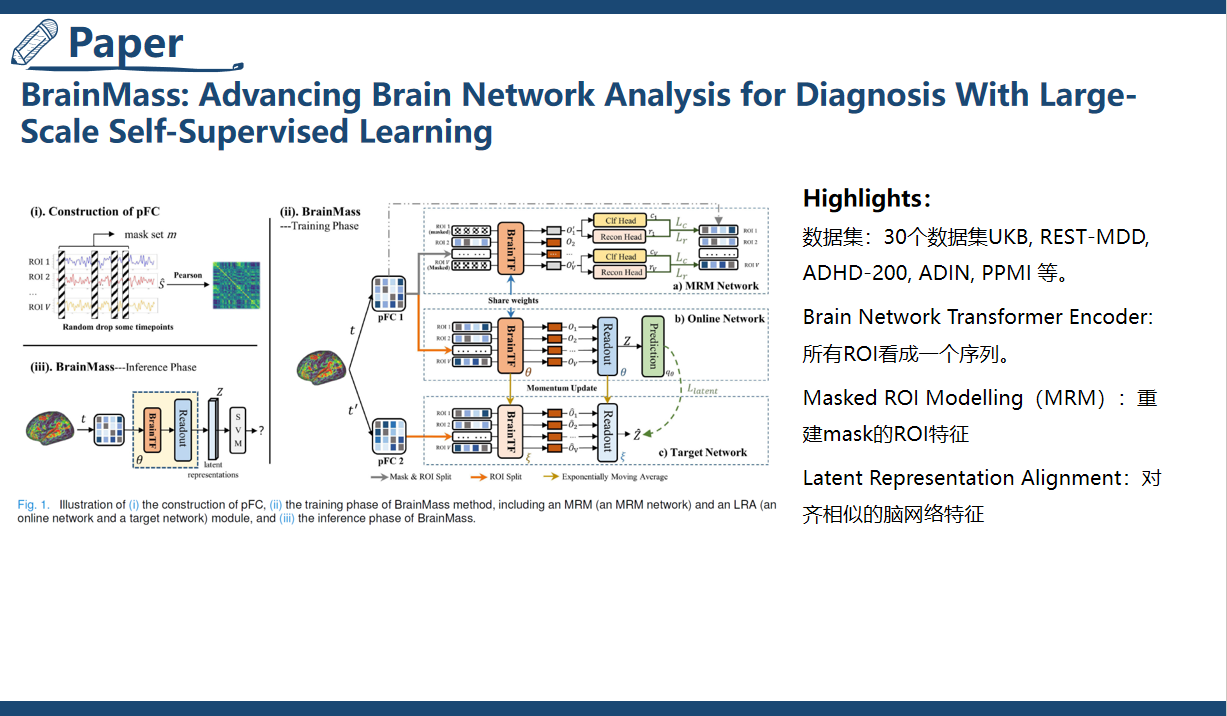
Paper 2: BrainMass: Advancing Brain Network Analysis for Diagnosis With Large-Scale Self-Supervised Learning
BrainMass代码链接:https://github.com/podismine/BrainMass
BrainMass简介
BrainMass is a foundation model designed for brain network analysis using large-scale self-supervised learning (SSL).
Keypoints
- pseudo-functional connectivity (pFC) : An augmentation method that generates more brain networks by randomly dropping timepoints in BOLD signals.
- Mask-ROI Modeling (MRM) : A technique that masks some ROIs and predicts their features by the remaining, enhancing intra-network dependencies and locality characteristics for downstream tasks.
- Latent Representation Alignment (LRA) : A module that ensures augmented brain networks from the same participant yield similar latent representations by aligning their embeddings. It employs a dual-branch approach to extract representations from two pFCs derived from the same BOLD signal and regularizes them.
fMRI
功能性磁共振成像(fMRI,Functional Magnetic Resonance Imaging) 是一种非侵入性的神经影像技术,用于测量大脑活动。fMRI的核心原理是基于血氧水平依赖(BOLD,blood-oxygen-level-dependent)效应。当大脑的某个区域活跃时,该区域的神经元会消耗更多的氧气,导致局部血流量增加。这种血流量变化会引起血液中氧合血红蛋白和脱氧血红蛋白比例的变化,进而影响磁共振信号的强度。
ROI
感兴趣区域(ROI,Region of Interest)是神经影像学中的一个重要概念,是研究者根据研究目标,在脑图像中定义的特定区域。ROI可以是一个单一的脑区,也可以是一组相关的脑区;可以是基于解剖结构的,也可以是功能连接的。
SSL
自监督学习(SSL,Self-Supervised Learning)是一种机器学习范式,旨在通过利用数据本身的结构或特性来生成监督信号,从而在没有大量标注数据的情况下训练模型。其核心思想是利用数据中的内在信息来生成伪标签(Pseudo-Labels),从而在没有人工标注的情况下训练模型。因此它与传统党的监督学习不同,不需要外部标注数据,而是通过设计预训练任务(Pretext Tasks)来学习数据的表示。
CNN
卷积神经网络(CNN,Convolutional Neural Networks)是一种专门用于处理具有网格结构数据(如图像、视频)的深度学习模型。其核心组件为卷积层,通过卷积核在输入数据上滑动,计算局部区域的加权和,提取数据特征并生成特征图。此外还有池化层、全连接层、激活函数等组成部分。
卷积操作具有局部连接和权重共享的特性,因此大大减少了参数数量。
GNN
图神经网络(GNN,Graph Neural Networks)是一类专门用于处理图结构数据(由节点和边组成)的深度学习模型。GNN通过消息传递机制,聚合节点的邻居信息并更新节点的特征表示,通过堆叠多层GNN,捕捉更远的邻居信息,从而获取全图结构的局部、全部特征。
GNN克服了传统神经网络在处理非欧几里得数据时的局限。
Transformer
Transformer 是一种基于自注意力机制(Self-Attention)的深度学习模型。自注意力机制是它的核心组件,通过计算元素之间的相关性动态分配注意力权重,从而更好地建模长距离依赖。此外,Transformer还有多头注意力机制(用于并行计算多个注意力头)、前馈神经网络、位置编码,以及编码器-解码器架构等组件。
Transformer模型克服了传统模型处理长距离依赖时的局限,具有良好的并行计算能力、可扩展性等特点